Period-Based Dimensional Modelling
TL;DR
Model facts at a consistent time grain, use surrogate keys for SCD Type 2, and enforce integrity in the model—even if your warehouse (like Amazon Redshift) doesn’t.
A lot of modern warehouse schemas optimise for query speed—but quietly give up on data integrity.
You see it in:
Many-to-many “relationships” that aren’t backed by keys
Fact and dimension data mixed together
No real enforcement of primary/foreign keys
Time handled via join predicates instead of structure
It works… until it doesn’t.
The core problem
An ERD should represent enforced structure.
A relationship line = a foreign key → which means many-to-one, not many-to-many.
If you have many-to-many, you don’t have a relationship—you have a missing intersection table.
When schemas are generated from join logic (rather than keys), you end up with:
No true primary keys → duplicates
No foreign keys → orphans
No normalisation → inconsistent facts
Period-based modelling (the fix)
Start with grain.
From Kimball methodology:
Define the grain of the fact (usually time-based)
Separate facts (measures) from dimensions (descriptive attributes)
Then enforce it structurally.
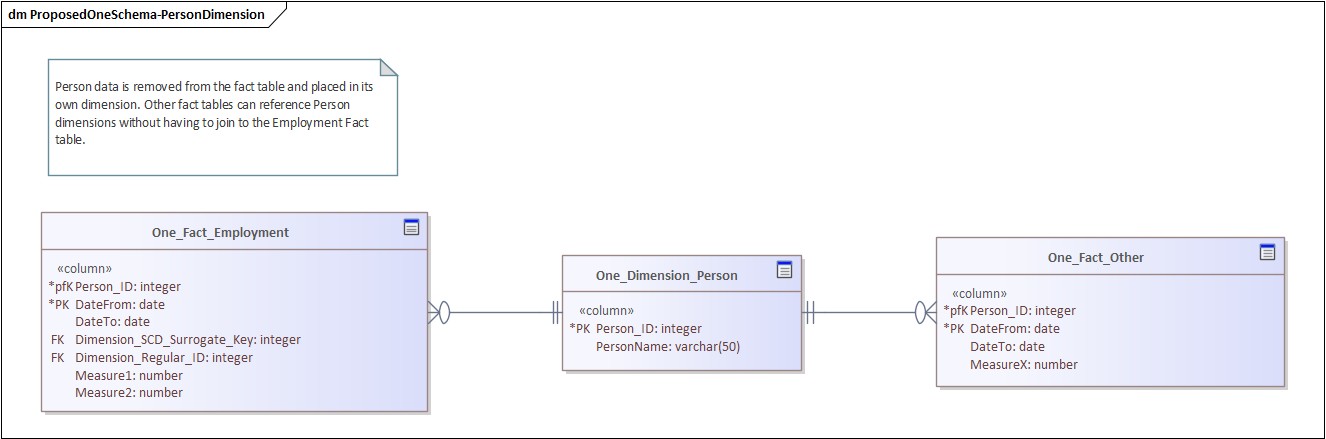
1. Separate Facts and Dimensions
If a fact table contains descriptive attributes (e.g. person data), you’ve coupled everything.
Instead:
Move attributes into a dimension (e.g. Person)
Let multiple fact tables reference it
This gives you:
Reusable dimensions
Cleaner joins
A Galaxy Schema with conformant dimensions
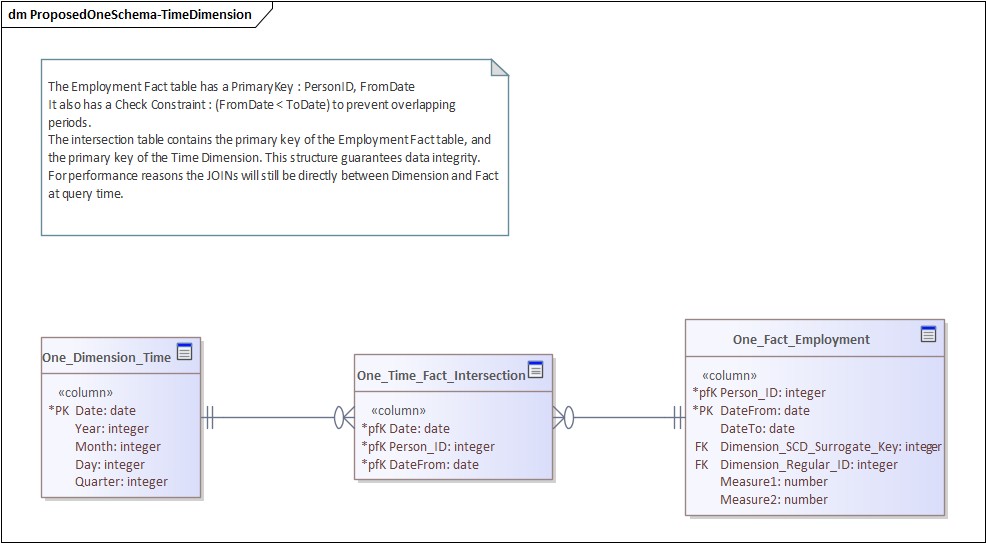
2. Model time properly
Direct joins to a time dimension are fast—but unsafe.
Better:
Introduce a time intersection / bridge table
Enforce FK relationships during load
Use it for validation, not necessarily querying
You keep performance and gain integrity.
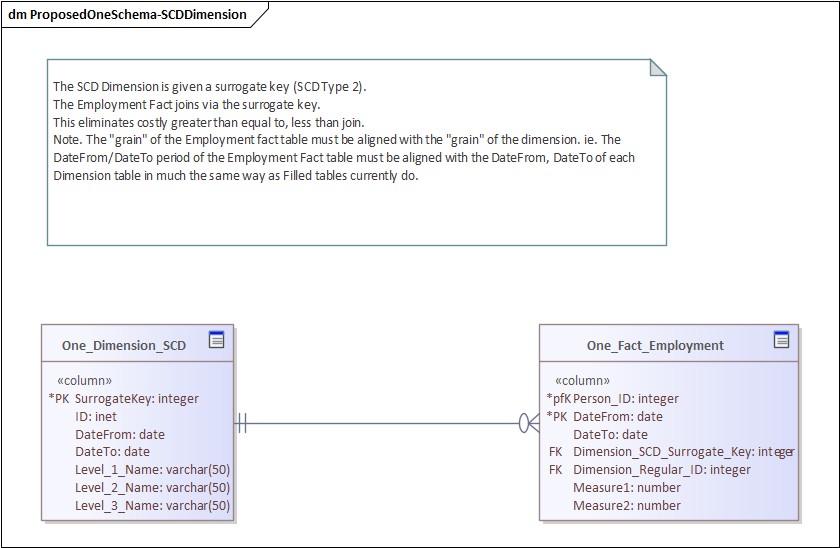
3. Fix Slowly Changing Dimensions (SCD)
Joining on (Id, FromDate, ToDate) is expensive and fragile.
Instead:
Use SCD Type 2
Introduce a surrogate key
Store that key in fact tables
Now joins are:
Simpler
Faster
Consistent
4. Align periods across the model
This is the part most systems miss.
If facts and dimensions all have time ranges:
Their periods must align
The fact table grain should match the lowest common grain across dimensions
This ensures:
Accurate joins
No temporal ambiguity
Predictable aggregations
My take
Performance-first schemas often cut out constraints because the engine won’t enforce them.
That’s backwards.
Even if the database doesn’t enforce integrity:
Your model should
Your load process should
Your DDL should reflect it
Bottom line:
If your joins define your model, you’ve already lost control of it.
Define the model first—especially time—and let everything else follow.
Data Model : Fact vs Dimension
Data Model : SCD Dimension
Data Model : Time Dimension